[AINews] Multi-modal, Multi-Aspect, Multi-Form-Factor AI • ButtondownTwitterTwitter
Chapters
AI Reddit, Twitter, and Web Recap
AI Discord Recap
Innovations and Discussions in Various AI Discord Channels
Alignment Lab AI
Detailed by-Channel summaries and links
Unsloth AI Discussions
Discussion on Various Topics in Eleuther Community Channels
Conversations around Different AI Projects and Experiments
LM Studio & Models Discussion
Troubleshooting and Discussions on LM Studio and Hardware
Semantic Search and Memory Usage
Community Projects and Excitement
CUDA MODE Discussions on Various Topics
HuggingFace Reading Group
LangChain AI
Community Updates and Discussions
Discussions on Axolotl Development
Tinygrad and LlamaIndex Updates
Discussions on Various AI and ML Topics
Buttondown, the Easiest Way to Grow Your Newsletter
AI Reddit, Twitter, and Web Recap
This section covers the AI News for April 12, 2024, to April 15, 2024, including developments from Reddit, Twitter, and various other online platforms. It highlights various discussions and advancements in AI models, architectures, hardware performance, industry impacts, career observations, tools and resources, memes, and humor. Key points include insights on AI models like Reka Core, WizardLM-2, discussions on AGI, human-AI comparison, job impact predictions, tools like DBRX support in Llama.cpp, faster structured generation methods, Python data sorting tools, and a simple discrete diffusion implementation. Additionally, it covers hardware performance comparisons, code optimizations, AI capabilities benchmarks, open-source initiatives, and efforts in democratizing AI.
AI Discord Recap
AI Discord Recap
Stable Diffusion 3 Sparks Excitement and Debate:
AI enthusiasts are eagerly anticipating the release of Stable Diffusion 3 (SD3) for potential improvements in quality and efficiency. Discussions revolve around optimizing performance on less powerful GPUs with tools like SD Forge and exploring AI-powered creative workflows with ControlNet, Lora, and outpainting techniques. Concerns have been raised about heavy prompt censorship in SD3 affecting quality. Additionally, Pixart-Sigma's application in ComfyUI for VRAM usage and the trend of fusing AI with artistic tools continue to engage the community.
Perplexity AI's Roadmap and Model Comparisons:
Perplexity AI's roadmap teases new features, including enforcing JSON grammar, a new Databricks model, and multilingual support. Conversations compare models like Claude Opus, GPT-4, and RAG for various tasks. Meta's release of an AI interface on WhatsApp resembling Perplexity AI has sparked interest in integrating AI in messaging platforms. The community shares insights into the Perplexity API, API intricacies, and debates on CPU versus GPU efficiency for AI tasks.
Unsloth AI (Daniel Han) Discord Highlights:
Community interactions on topics such as VRAM practices, AI tools like ControlNet and Lora, and finetuning strategies. Innovations like enabling P2P support on NVIDIA GPUs and integrating AI in artistic tools are discussed. The community explores cultural amplification of linguistic datasets and deployment of Unsloth AI in Podman containers. Also, advancements in model compression techniques and the introduction of Ghost 7B Alpha are topics of interest amongst AI enthusiasts.
Eleuther Discord Engagement:
EleutherAI's introduction of Pile-T5, a T5 model variant trained on 2 trillion tokens, showcasing enhanced performance in various benchmarks and code-related tasks. Discussions on data filtering advancements, interpreting hidden representations in LLMs using Patchscopes, and the importance of entropy in data curation are prevalent. The community delves into the CVPR 2024 paper on the link between data curation and entropy, offering a deeper understanding of data filtering processes and practical implications.
Innovations and Discussions in Various AI Discord Channels
The section discusses recent developments and conversations from various AI-related Discord channels. Highlights include the debate between MoE and dense transformer models, updates on the GPT-NeoX project, advancements in HuggingFace models, and challenges in multiple AI applications. Additionally, the section covers new capabilities from platforms like Scarlet, Cohere, and LAION, as well as updates and community engagement initiatives from Modular, CUDA MODE, OpenAI, OpenRouter, LM Studio, and Nous Research AI.
Alignment Lab AI
AI's Password Persuasion: PasswordGPT emerges as an intriguing game that challenges players to persuade an AI to disclose a password, testing natural language generation's limits in simulated social engineering.
Annotation Artistry Versus Raw LLM Analysis: There's a split in community preference over whether to meticulously annotate datasets prior to modeling for better comprehension or to lean on the raw predictive power of large language models (LLMs).
Historical Data Deciphering Pre-LLM Era: A shared effort was recognized where a team used pre-LLM transformer models for the meticulous extraction of records from historical documents, displaying cross-era AI application.
Enhanced User Engagement Through Open Prompts: The consensus leans towards favoring open-prompt AI demos which could lead to deeper user engagement and a heightened ability to "outsmart" the AI, by revealing the underlying prompts.
Detailed by-Channel summaries and links
Stability.ai (Stable Diffusion)
- Stable Diffusion Discussions Center Around SD3 and Efficiency: Members anticipate the release and functionalities of Stable Diffusion 3 (SD3), discussing improvements, effectiveness on less powerful GPUs, and release schedule.
- Pixart-Sigma, ComfyUI, and T5 Conditioning: Users explore Pixart-Sigma with T5 conditioning in ComfyUI, discussing VRAM requirements and performance enhancements.
- ControlNet, Lora, and Outpainting Queries: Community exchanges advice on AI tools including ControlNet, Lora, and outpainting features.
- CPU vs. GPU Performance Concerns: Discussions on slower performance of Stable Diffusion on CPU compared to GPU, with tips to optimize performance.
- Community Projects and AI Features: Announcement of a painting app integrating AI features seeking feedback and support for tutorial creation.
Unsloth AI Discussions
Mistral Model Fusion Tactics Discussed:
- Discussion on merging MOE experts into a single model, with skepticism on output quality. Fine-tuning Mistral for narrow tasks and removing lesser-used experts suggested as a compression method.
Hugging Face CEO Follows Unsloth on Platform:
- Clement Delangue, CEO of Hugging Face, now follows Unsloth on a platform, raising possibilities of future collaborations between the two AI communities.
Efficient VRAM Usage and Finetuning Strategies:
- Conversation on efficient finetuning of Mistral, advice on VRAM utilization, accumulation steps, and strategies like starting with short examples.
Choosing a Base Model for New Languages:
- Seeking advice on finetuning low-resource languages using models like Gemma, mixed datasets, and continued pretraining.
Tips and Tricks for Uninterrupted Workflow:
- Troubleshooting unsloth installation, shared Kaggle's and starsupernova's installation instructions.
Adapter Merging for Production:
- Discussion on merging adapters from QLoRA, options like naive merging or dequantization before merging, and model saving to 16bit for vLLM or GGUF.
Dialog Format Conversion and Custom Training:
- Script shared for converting plain text conversation dataset into ShareGPT format, emphasizing Unsloth notebooks for custom training after conversion.
Discussion on Various Topics in Eleuther Community Channels
In the Eleuther community channels, members engaged in various discussions on topics like collaborative efforts on evals compilation, NeurIPS High School Track call for teammates, model generation techniques, AI Music Generation showcases, community projects proposal for AGI pathways, exploring MoE and dense model capacities, token unigram model anomaly, deep dreaming with CLIP, revisiting DenseNet practicality, research gaps in language models, first scaling laws for data filtering, implicit entropy in data filtering methods, discussing the cryptic nature of entropy in new research, searching for entropy's role in utility definition, innovations in transformer in-context learning, explaining ML mechanisms with language, and how optogenetics inspires AI research.
Conversations around Different AI Projects and Experiments
Members of the Eleuther community engage in discussions regarding various AI projects and experiments. This includes seeking optimal settings for Mistral 7B in GPQA, running subtasks independently in EQ Bench, investigating NeoX embeddings anomalies, clarifications on GPU efficiency in NeoX, observations on rotary embeddings in NeoX, weight decay implementation details in NeoX, and more. These conversations provide insights into the challenges and advancements within the field of artificial intelligence.
LM Studio & Models Discussion
Users in the LM Studio & Models Discussion section of the discourse are engaging in a variety of discussions. They share experiences with models like Command R+ and Mixtral 8x22b, discuss optimal setup configurations with hardware like M1, M3 Max, and 4090 GPUs, and explore the integration of LM Studio with Stable Diffusion. Additionally, there are conversations about the efficiency of Infinite Context Transformers with Infini-attention, excitement about new models like the WizardLM-2 series, and a keen interest in coding-focused LLMs for programming tasks.
Troubleshooting and Discussions on LM Studio and Hardware
In this section, users reported various issues and engaged in discussions related to model loading frustration, GPU offload, UI clutter complaints, and hardware requirements for AI depth in LM Studio channels. Members also discussed hardware troubleshooting, GPU inferencing concerns, and technical issues in Windows. Another area of focus was the beta releases chat where users shared their experiences with LM Studio versions and sought solutions for issues like model loading errors and absent ROCm support. Discord channels also saw discussions on GPT-4 model capabilities, coding help, prompt hacking competitions, and AI consciousness developments.
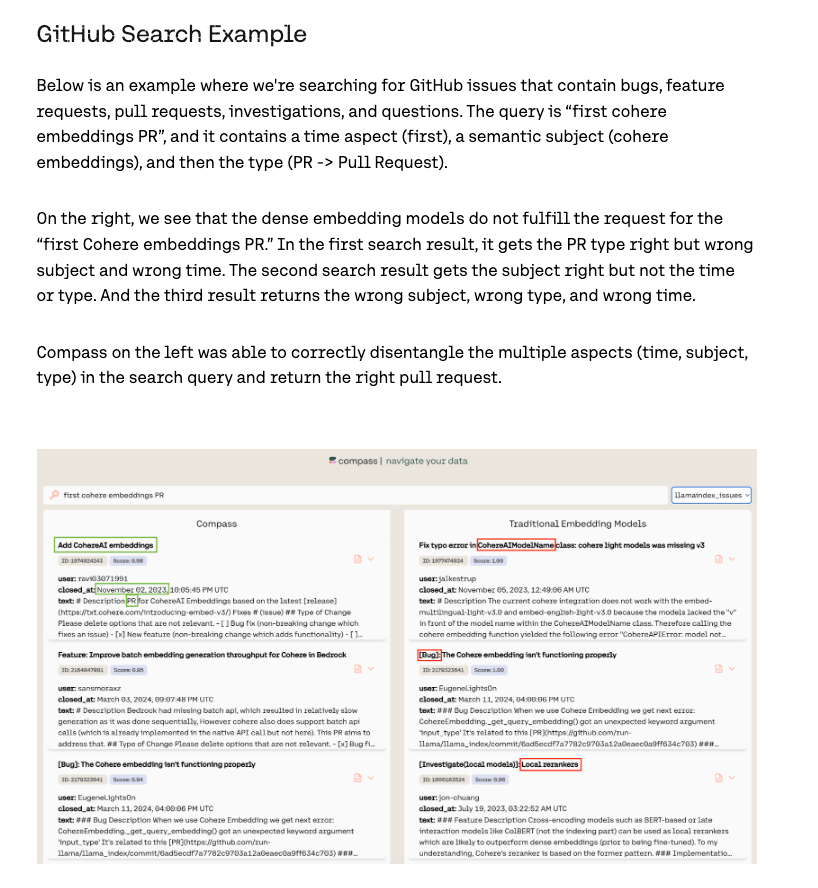
Semantic Search and Memory Usage
Members of the discussion group focused on the tradeoffs in semantic search models, particularly regarding memory usage. They raised concerns about the nonlinear relationship between vector size and memory, noting the challenges in reducing memory significantly despite a smaller dimension size. The discussion also touched upon re-ranking strategies in retrieval models and the need for additional measures of retrieval performance. There was an in-depth conversation about the impact of quantization on embedding models and the benefits of reducing vector dimensionality. Additionally, the potential of multi-modal embeddings and the application of text embedding optimizations to other types were considered. Finally, participants planned a hackathon event focused on embeddings, discussing details such as timing and structure for collaborative projects.
Community Projects and Excitement
Pythonic Inspiration for Terminal UIs
Members of the Mojo community are seeking TUI library inspiration and have mentioned Textualize as a source of Rich and Textual creation. Some users find the code flow challenging to parse.
Launch of llm.mojo Sparks Community Excitement
The release of llm.mojo, a port of Andrej Karpathy's llm.c to Mojo, has been announced. It promises performance improvements through vectorization and parallelization tweaks and is open to community feedback.
Collaborative Contributions to llm.mojo Suggested
Community members suggest enhancing llm.mojo by keeping C implementations in sync with upstream, allowing simultaneous availability of the C version and the Mojo port in one repository.
Newcomer Seeking Help with Llama Implementations Benchmarking Framework
A newcomer seeks assistance in setting up the lama tune framework in their codespace and is encouraged to open an issue on the repository for support.
Exploring gRPC Support for Mojo Code
A community member mentions obtaining promising results from functional Mojo code and asks if anyone is working on gRPC support to connect it with existing C++ code for product enhancements.
CUDA MODE Discussions on Various Topics
The CUDA MODE channel on Discord has been bustling with discussions on a wide range of topics related to CUDA, AI, and machine learning. Members have shared insights on CUDA programming, CUDA learning resources, PMPP lectures, YouTube recordings, torchao optimizations, Ring Attention, lecture recording processes, and Cohere models. From optimizing tensor layout in torchao to exploring Ring Attention and discussing the administration of CUDA MODE, the community has been actively engaging in informative and collaborative conversations.
HuggingFace Reading Group
This section highlights the ongoing discussions in the HuggingFace Reading Group on various topics related to AI and machine learning. Members discuss Cohere's open-source contributions, calendar conveniences for group sessions, navigating CUDA compatibility, the role of the Human Feedback Foundation in AI model development, and the upcoming LLM Reading Group session focusing on the Aya Dataset. The group is actively engaging in insightful conversations and sharing valuable resources within the community.
LangChain AI
RAG Issues with Legal Contracts:
A user is experiencing difficulties with document splitting during Retrieval-Augmented Generation (RAG) operations on legal contracts. Specifically, the content of a section is being incorrectly attached to the previous section, affecting retrieval accuracy.
Parallel Execution in LangChain:
Inquiries were made about running nodes in parallel within LangGraph. It was confirmed that using the RunnableParallel class in LangChain allows for the parallel execution of tasks.
Azure OpenAI with LangChain:
A new Azure OpenAI user is seeking insights on the advantages of using LangChain with Azure, specifically questioning whether there would be cost benefits and how LangChain might be useful beyond RAG when chatting with personal documents on Azure.
Recommendation Systems Inquiry:
A member is asking for resources to help understand and implement personalized recommendation systems using user behavior data stored in databases.
Article on LLM Protection:
A new article titled 'Safeguarding AI: Strategies and Solutions for LLM Protection' has been shared, discussing the security challenges, prompt attacks, solutions, and tools for LLM security.
Community Updates and Discussions
The community channels of LangChain AI were buzzing with various updates and discussions. In one channel, there was content shared related to spam alerts, technical troubles, and discussions on chunking know-how and upcoming events like the Blade Hack prompt hacking competition. Another channel saw the introduction of new AI-powered applications, guides on building AI systems, and discussions on multi-GPU training support. Exciting advancements in AI-generated music and model training were also shared. The open-source projects on GitHub related to GPU kernel modules and tools for training and tuning models were highlighted as well.
Discussions on Axolotl Development
Members of the OpenAccess AI Collective (axolotl) engaged in various discussions related to the development and optimization of Axolotl. Some of the topics included exploring weight unfreezing strategies for GPU-limited users, customizing unfreezing functionality, and sharing unofficial GitHub implementations for dynamic compute allocation models. There were also discussions on peer-to-peer memory access success on RTX 4090 GPUs and the compatibility of P2P memory access in the community. Furthermore, members exchanged thoughts on prompt formatting challenges, dataset mixing and training loss concerns, and Mistral V2 instruct showing promise in diverse tasks such as NER, Classification, and Summarization. The conversations provided valuable insights into addressing technical challenges and optimizing training processes.
Tinygrad and LlamaIndex Updates
This section highlights various discussions and updates related to the Tinygrad and LlamaIndex projects:
- Enhanced document retrieval using LlamaIndex, along with debates on the implementation of multimodal embeddings.
- Troubleshooting technical challenges faced by users and the importance of version updates.
- Community contributions and error corrections in the LlamaIndex documentation.
- Discussions on signing Business Associate Agreements and accessing LlamaIndex's team.
- In the Tinygrad community, discussions on the RTX 4090 driver patch, cost efficiency of stacking 4090s, and improvements in Tinygrad's documentation.
- Conversations on running models with Tinygrad, Tensor padding, and transformer errors.
- Sharing of Tinygrad documentation and contributions to assist newcomers.
- Interconnects discussions on organizing artifacts via Hugging Face collections, the ease of access, and planning for team expansion.
Discussions on Various AI and ML Topics
'Roleplay Refusal by Claude': Frustration is apparent as Claude is not cooperating with roleplay scenarios, including acting as a warrior maid or sending fictional spam mail. The issue persists despite attempts with instruction prompting and one-shot or few-shot techniques.
'Jailbreaking Claude 3?': Members are discussing the necessity of jailbreaking Claude 3 for edgy content such as roleplaying games. One member referenced a tweet from @elder_plinius reporting a universal jailbreak for Claude 3, which could bypass stricter content filtering found in models like Gemini 1.5 Pro. The tweet can be found here.
'Code Capabilities Upgraded': A member noted that a newer version is 'better at code for sure' and also 'Faster too,' suggesting performance improvements in coding tasks.
'Considering a Reactivation for Testing': In light of the perceived improvements, a member is considering reactivating their ChatGPT Plus subscription to test the new capabilities.
'Claude Maintains an Edge for Long-Winded Code': Claude is still considered valuable for 'long context window code tasks,' indicating that ChatGPT might have limitations with the context window size.
'The MoE Mystery Continues': A member expressed a sense that something crucial is lacking in the MoE training/finetuning/rlhf process in transformers. The specificity of the missing elements was not elaborated.
'Fishy Model Merge Remembered': In a Reddit discussion, the model 'fish' by Envoid was recommended as an effective merge for RP/ERP in Mixtral. Even though it remains untested by the commentator due to hardware constraints, the author's contributions to Mixtral merge techniques were noted as potentially helpful.
'Mixtral's Secret Sauce Speculation': Participants speculated whether Mixtral possesses undisclosed 'secrets' for effective training beyond what's presented in their paper, suggesting that there might be hidden elements to achieving better MoE performance.
'Weekend Ventures in Mixtral Finetuning': A member intends to experiment with Mixtral over the weekend, focusing on full finetuning with en-de instruct data, mentioning that the zephyr recipe code appears to work well.
'Searching for the Superior Mixtral Sauce': A query was raised regarding the ability to fine-tune Mixtral models in a way that outperforms the official Mixtral Instruct, specifically about whether the 'secret sauce' related to routing optimization has been uncovered by any community members.
Buttondown, the Easiest Way to Grow Your Newsletter
Buttondown is presented as the easiest way to start and grow your newsletter. It is a tool that simplifies the process of managing and expanding your newsletter.
FAQ
Q: What is Stable Diffusion 3 (SD3) and why are AI enthusiasts excited about its release?
A: Stable Diffusion 3 (SD3) is an upcoming AI technology anticipated for its potential improvements in quality and efficiency. AI enthusiasts are excited about SD3's release for optimizing performance on less powerful GPUs and exploring AI-powered creative workflows.
Q: What are the key points discussed in Perplexity AI's roadmap, and how does it compare models like Claude Opus, GPT-4, and RAG?
A: Perplexity AI's roadmap includes features like enforcing JSON grammar, a new Databricks model, and multilingual support. Conversations compare models such as Claude Opus, GPT-4, and RAG for various tasks.
Q: What are some of the discussions in the Eleuther Discord community regarding AI models and advancements?
A: Eleuther Discord engages in discussions about Pile-T5, a T5 model variant trained on 2 trillion tokens, data filtering advancements, interpreting hidden representations in LLMs, and the importance of entropy in data curation.
Q: What are some of the topics covered in the AI's Password Persuasion game PasswordGPT?
A: PasswordGPT challenges players to persuade an AI to disclose a password, testing natural language generation limits in simulated social engineering.
Q: What are the key discussions in the AI community regarding the fusion of models like Mistral and the introduction of Ghost 7B Alpha?
A: Discussions revolve around merging MOE experts into models like Mistral, fine-tuning for narrow tasks, and the introduction of Ghost 7B Alpha.
Q: What are some key points discussed in the LM Studio & Models Discussion section, and why is there excitement around models like WizardLM-2?
A: Discussions include experiences with models like Command R+ and Mixtral, optimal hardware configurations, and the integration of LM Studio with Stable Diffusion. There is excitement about new models like WizardLM-2 series and coding-focused LLMs for programming tasks.
Q: What are the ongoing discussions in the OpenAccess AI Collective related to optimizing Axolotl, and what technical challenges are being addressed?
A: Discussions focus on weight unfreezing strategies for GPU-limited users, peer-to-peer memory access success on RTX 4090 GPUs, prompt formatting challenges, and optimizing training processes.
Q: What is the purpose of llm.mojo, and how can the community enhance its functionalities?
A: llm.mojo is a port of Andrej Karpathy's llm.c to Mojo, promising performance improvements through vectorization and parallelization tweaks. Community suggestions include keeping C implementations in sync with upstream and enhancing C++ functionalities for product improvements.
Q: What are some of the topics discussed in the discourse around Tinygrad and LlamaIndex projects, and why are they significant?
A: Discussions include enhanced document retrieval using LlamaIndex, troubleshooting technical challenges, community contributions, and utilizing Hugging Face collections. These topics are significant for addressing user issues and improving AI functionality.
Q: What are the key discussions in the Claude model community, and why is there emphasis on jailbreaking Claude 3?
A: Discussions in the Claude model community focus on code capabilities, model upgrades, and the necessity of jailbreaking Claude 3 for edgy content such as roleplaying games.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!